Data Science Fundamentals (အချက်အလက်သိပ္ပံအခြေခံ)
AI, Machine Learning and Data Science
credit Dr Tun T. Thet

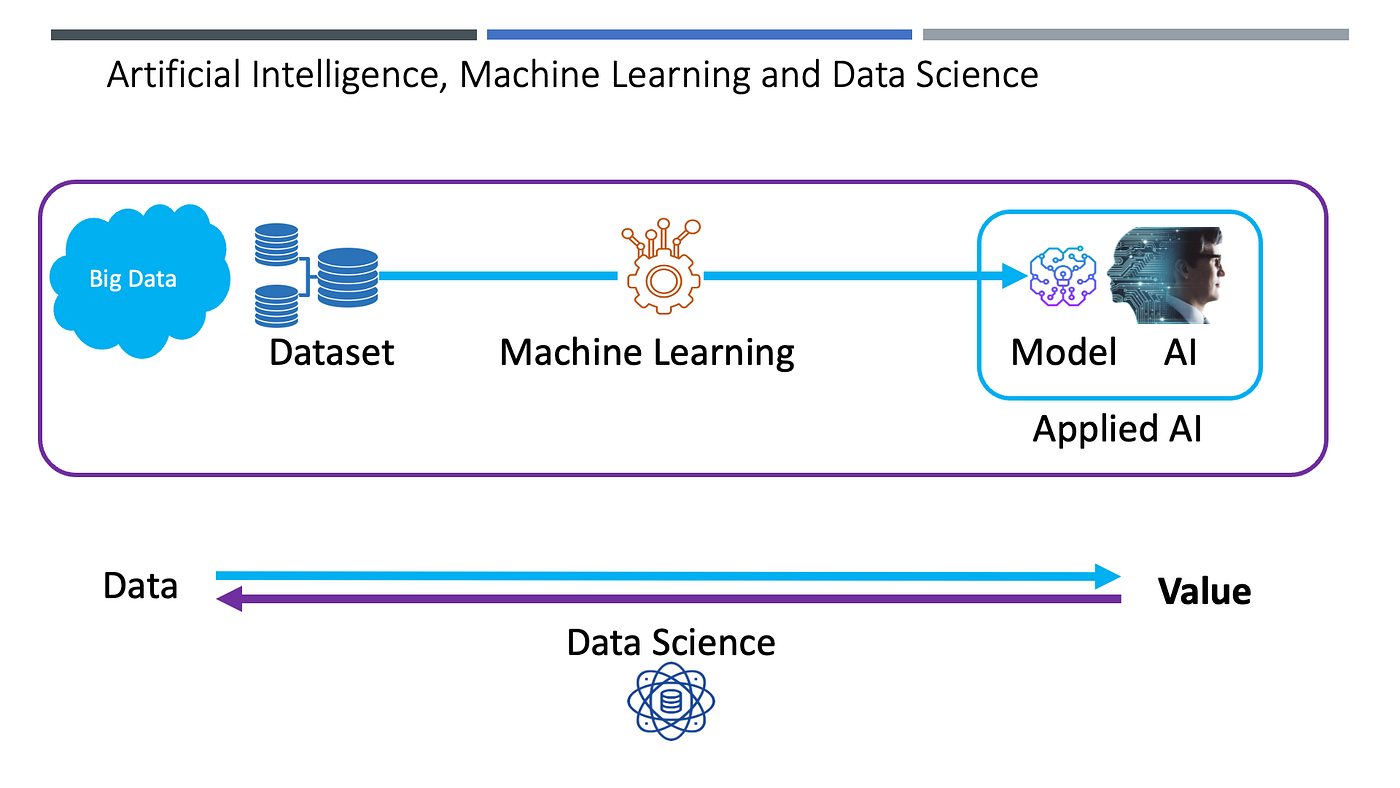
Data Science (အချက်အလက်သိပ္ပံ) လို့ ပြောရင်ကျယ်ပြန့်ပါတယ်။ယေဘုယျအားဖြင့်တော့ အချက်အလက်များကို စာရင်းအင်းနှင့် သိပ္ပံပညာနည်းလမ်းတွေသုံးပြီ တန်ဖိုးထုတ်ယူခြင်းလို့ ဆိုပါတယ်။ Machine Learning (စက်လေ့လာမှု) ဆိုတာကတော့ စုစည်းထားတဲ့အချက်အလက်တွေကို အသုံးချပြီး AI စွမ်းဆောင်ရည်ရယူခြင်း နည်းလမ်းတစ်ခု ဖြစ်ပါတယ်။ AI (ဉာဏ်ရည်တု) ဆိုတာကတော့ လူသားတွေမှာရှိကြတဲ့ ပြဿနာဖြေရှင်းနိုင်စွမ်းတွေ၊ ဆုံးဖြတ်နိုင်စွမ်းတွေ၊ သိမြင်နိုင်စွမ်းတွေကို ကွန်ပျူတာဖြင့် အတုယူ စွမ်းဆောင်ခြင်း ဖြစ်ပါတယ်။

AI အကြောင်းကို စတင်ပြောဆိုခဲ့ကြတာတော့ ကြာပါပြီ။ ၁၉၄၀ လောက်ကတည်းက စတင်ပြောဆိုခဲ့၊ စတင်လေ့လာခဲ့ကြတာပါ။ အစပိုင်းမှာတော့ လူတွေကသတ်မှတ်ပေးတဲ့ ညွန်ကြားချက်တွေကို အတိအကျ ကွန်ပျူတာက လိုက်လုပ်တဲ့ပုံစံမျိုးနဲ့ AI ကိုစတင် အကောင်အထည်ဖေါ်ခဲ့ကြတာဖြစ်ပါတယ်။ Machine Learning ပေါ်ပြီးနောက်ပိုင်းမှာတော့ ညွန်ကြားချက်တွေ ပေးစရာမလိုအပ်တော့ဘဲ အချက်အလက်တွေကို ကွန်ပျူတာဖြင့် လေ့လာပြီး AI စွမ်းဆောင်ရည်ကို အကောင်အထည့်ဖေါ်လို့ရလာပါတယ်။ Machine ဆိုတာ ကွန်ပျူတာကို ဆိုလိုတာပါ။ နောက်ပိုင်းမှာတော့ Big Data တို့၊ Deep Learning တို့ ပေါ်လာပြီးနောက်ပိုင်းမှာ Unstructured Data အမျိုးအစားတွေဖြစ်တဲ့ ရုပ်ပုံတွေ၊ ဗီဒီယိုတွေ၊ လူမှုကွန်ယက်နဲ့ IoT Devices များမှ မျိုးစုံသော အချက်အလက်တွေကိုပါ အသုံးချလာနိုင်ပြီး AI စွမ်းဆောင်ရည်တွေဟာ တစ်ဆထက်တစ်ဆ ပိုမိုတိုးတက်လာကြပါတယ်။ ဒီလို အချက်အလက်တွေမှ Value တန်ဖိုးထုတ်ယူခြင်းဖြစ်တဲ့ ဒီလုပ်ငန်းစဉ်တွေကို Data Science လို့ခေါ်ပြီး၊ ဒီလုပ်ငန်းစဉ်တွေကို ဆောင်ရွက်သူတွေကို Data Scientists (အချက်အလက်သိပ္ပံပညာရှင်) လို့ ခေါ်ဆိုကြတာ ဖြစ်ပါတယ်။ Machine Learning လုပ်ငန်းစဉ်များကို အကောင်အထည်ဖေါ်ဆောင်ရွက်တဲ့သူတွေကို Data Scientists လို့ခေါ်ဆိုတာပါ။ ဒီလုပ်ငန်းစဉ်ကနေ ရလဒ်အဖြစ်ထွက်လာတဲ့ AI စွမ်းဆောင်ရည်တွေကို ဆော့ဝဲတွေမှာ ထည့်သွင်းချိတ်ဆက် အသုံးပြုတဲ့သူကိုတော့ AI Engineer (အေအိုင်အင်ဂျင်နီယာ) လို့ ခေါ်ကြပါတယ်။ Data Scientists နှင့် တွဲဖက်လုပ်ကိုင်ကြသော အခြားအသက်မွေးဝမ်းကြာင်းများလည်းရှိပါတယ်။ Data Engineering ဆိုတာကတော့ Data Lake, Data Warehouse နှင့် Data Factory တိုကို ကိုင်တွယ်ဆောင်ရွက်ရတာဖြစ်ပါတယ်။ BI and Analytics လို့ပြောရင်တော့ Dashboard တွေ၊ Analysis တွေ၊ Insights တွေ၊ Visualization တွေကို အကောင်အထည်ဖေါ်ဆောင်ရွက်ရတာဖြစ်ပါတယ်။

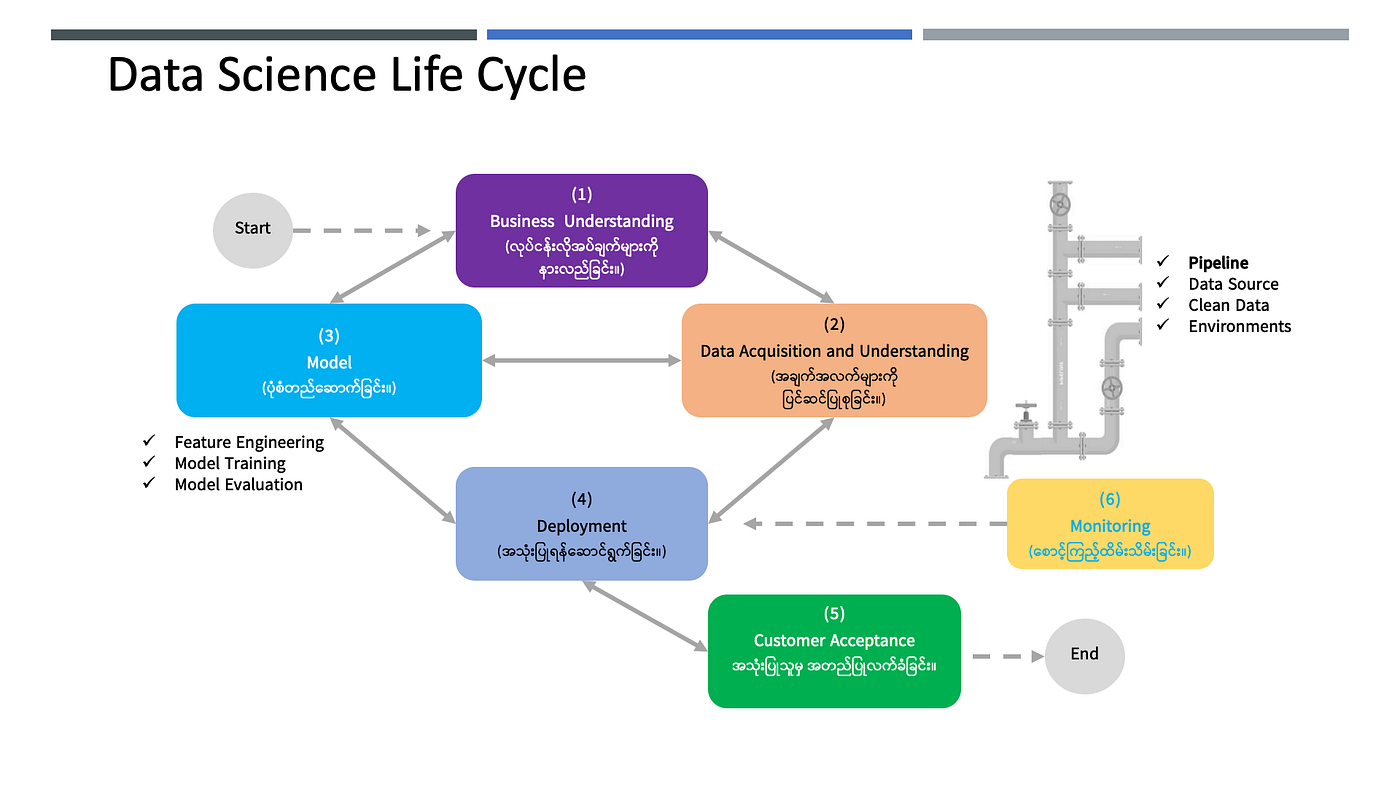
Data Science Life Cycle ဆိုတာကတော့ Data Science လုပ်ငန်းစဉ်ကို အဆင့်ဆင့် ဆောင်ရွက်ခြင်း၊ လည်ပတ်ခြင်းဖြစ်စဉ် လို့ပြောရပါမယ်။
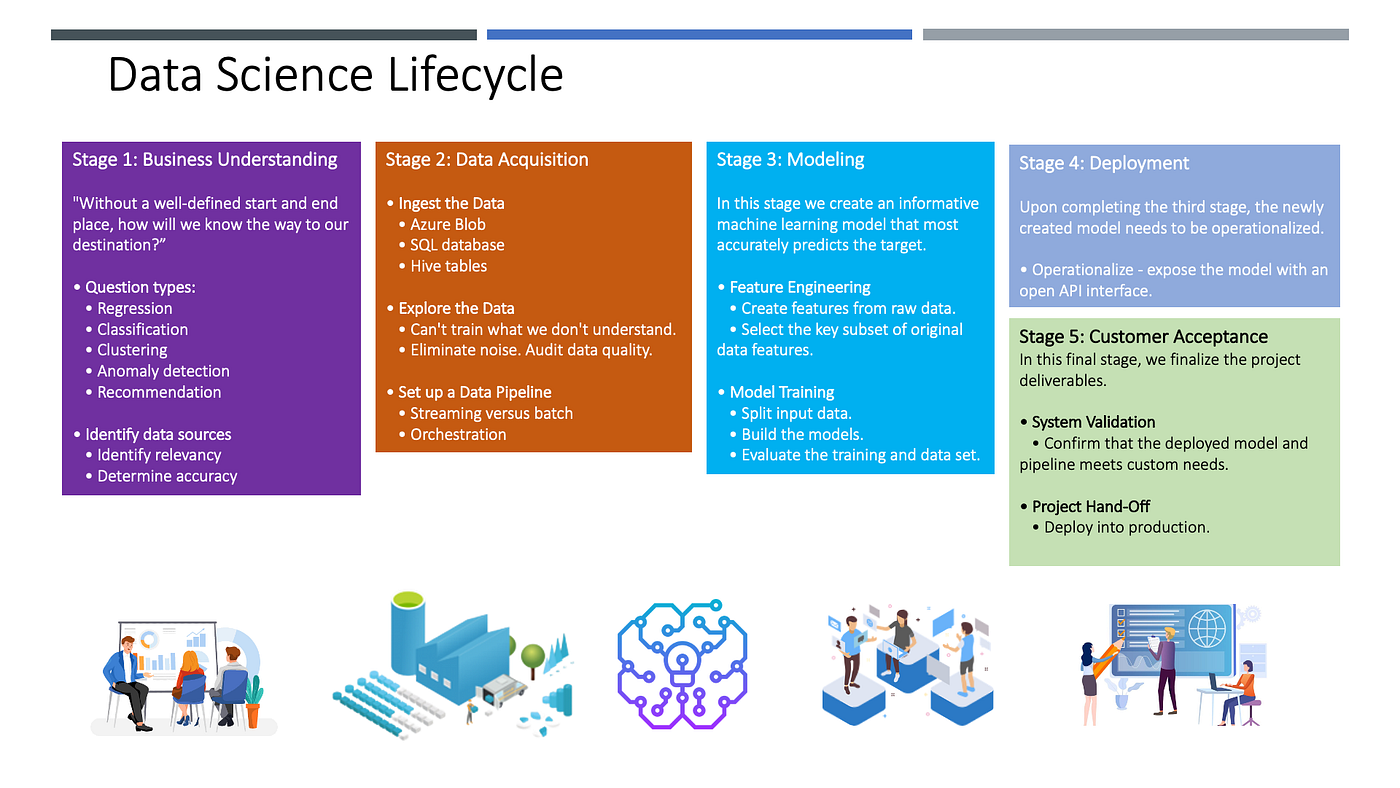
နံပါတ် (၁)၊ လုပ်ငန်းလိုအပ်ချက်ကို နားလည်ခြင်းနဲ့ စတင်ပါတယ်။ သုတေသီတွေကတော့ သုတေသနပုစ္ဆာ Research Question (သို့) Research Problem လို့ပြောကြပါတယ်။ လုပ်ငန်းတွေမှာ ဆိုရင်တော့ ဆောင်ရွက်လိုတဲ့ ရည်မှန်းချက် (Goal) လို့လည်း ပြောလို့ ရပါတယ်။ ဘယ်ပုစ္ဆာကို ဖြေရှင်းရမယ် ဆိုတာကို နားလည်သဘောတူပြီးမှ Data Science လုပ်ငန်းစဉ်ကို စတင်ရမှာ ဖြစ်ပါတယ်။
နံပါတ် (၂) အနေနဲ့ကတော့ အချက်အလက်တွေကို ရယူခြင်း၊ နားလည်အောင်ဆောင်ရွက်ခြင်းလို့ပြောရပါမယ်။ အချက်အလက်တွေ ဘယ်က (Data Lake, Data Warehouse etc) ရမှာလဲ၊ ဘယ်လိုပုံစံတွေနဲ့ယူရမှာလဲ၊ ဘယ်လို ပြန်လည်ပြင်ဆင်ပေးဖို့လိုမှာလဲ၊ အစသဖြင့် နားလည်ဖို့လိုပါတယ်။ Big Data လို့ပြောတဲ့အတွက် Structured Data ၊ Semi-structured Data နှင့် Unstructured Data အားလုံးပါဝင်နိုင်ပါတယ်။ ဒီနေရာမှာတော့ Data Engineer တွေနဲ့ တွဲဖက်လုပ်ကိုင်ဆောင်ရွက်ဖို့လည်း လိုအပ်လာနိုင်ပါတယ်။
နံပါတ် (၃) အနေနဲ့ကတော့ ဒီအချက်အလက်တွေကို အခြေခံပြီး Model ပုံစံ တည်ဆောက်ခြင်းဖြစ်ပါတယ်။ Model ကိုတော့ နားလည်လွယ်အောင်ပြောရင် AI ရဲ့ ဦးနှောက်လို့ တင်စားပြောလို့ရပါတယ်။ ဒီအဆင့်မှာ Training နှင့် Evaluation တို့ပါဝင်ပါမယ်။ Model ကို Training လုပ်တယ် လို့လည်း ပြောကြပါတယ်။ လိုအပ်ချက်တွေနဲ့ ကိုက်ညီမှု ရှိမရှိသုံးသပ်တာ Evaluation တွေလည်း လိုအပ်ပါတယ်။
နံပါတ် (၄) ကတော့ ဒီ Model ကို အသုံးပြုရန် ဆောင်ရွက်ခြင်း တပ်ဆင်ခြင်းပဲ ဖြစ်ပါတယ်။ Deployment (သို့) Production လို့လည်း ခေါ်ပါတယ်။ Real-time (သို့) Batch အသုံးပြုတာနှစ်မျိုးလုံးဖြစ်နိုင်ပါတယ်။ AI ရဲ့ Endpoint ထုတ်ပေးပြီး Integration ပြုလုပ်တာတွေ ပါဝင်ပါတယ်။
နံပါတ် (၅) ကတော့ နံပါတ် (၁) မှာ သတ်မှတ် သဘောတူခဲ့ကြတဲ့ ပုစ္ဆာ၏လိုအပ်တွေချက်နဲ့ ကိုက်ညီမှုရလဒ်ကို ပြန်လည်စစ်ဆေးတာဖြစ်ပါတယ်။ User Acceptatne Test (UAT) သဘောမျိုးလည်းဖြစ်ပါတယ်။ ဒီလိုဆောင်ရွက်တဲ့အခါမှာလည်း Objective ဖြစ်နိုင်သမျှဖြစ်ဖို့ လိုအပ်ပါတယ်။
နံပါတ် (၆) အဆင့်ကတော့ အချက်အလက်တွေကို ပုံမှန်စောင့်ကြည့်ပြီး ရှေ့ဆက်ဖြစ်ပေါ်လာနိုင်မည့် အပြောင်းအလဲတွေကြောင့် Model ကို ပြန်လည် Training ပြုလုပ်ရန်၊ ပြန်လည်တည်ဆောက်ရန် လိုမလို သုံးသပ်တာတွေ ပါဝင်ပါတယ်။
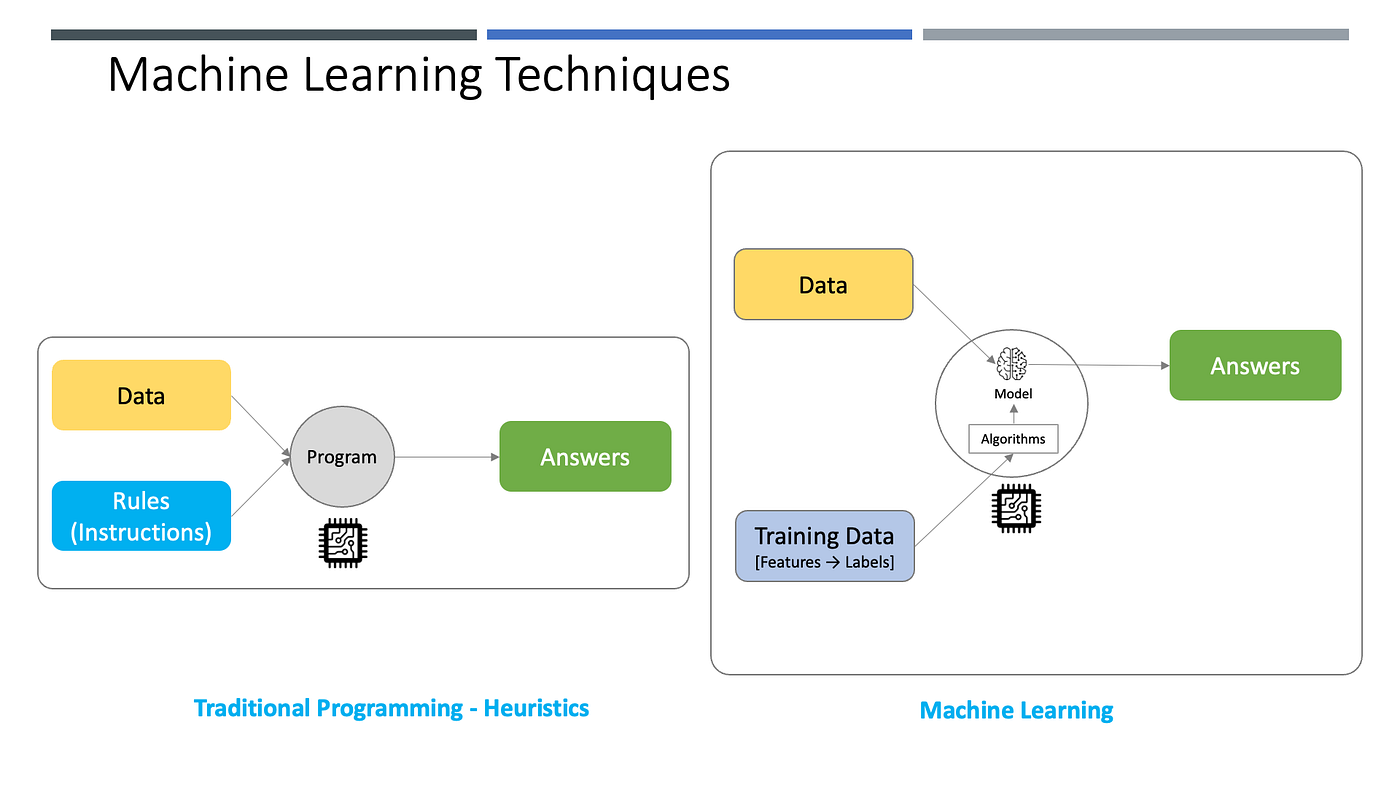
ပုံမှန် Program တွေကို ရေးသားတဲ့အခါမှာ “ဘာဆိုရင် ဘယ်လို” ဆိုတဲ့ သတ်မှတ်ချက် Rules တွေကို ရေးပေးဖို့လိုပါတယ်။ Machine Learning နည်းလမ်းကတော့ စုစည်းထားတဲ့ အချက်အလက်တွေကို ပေးရုံနှင့် Rules တွေမလိုအပ်တော့ဘဲ Model ကိုတည်ဆောက်ပေးနိုင်ပြီး၊ ဒီထွက်လာတဲ့ Model ကို အသုံးချပြီး AI စွမ်းဆောင်ရည် ရရှိနိုင်တာဖြစ်ပါတယ်။ ကွန်ပျူတာကို အချက်အလက်နဲ့ သင်ပေးတာဖြစ်တဲ့ အတွက် Training လုပ်တာလိုလည်းခေါ်ကြပါတယ်။ ဒါကြောင့် Machine Learning နည်းလမ်းလို့ ခေါ်ဆိုကြတာလည်း ဖြစ်ပါတယ်။
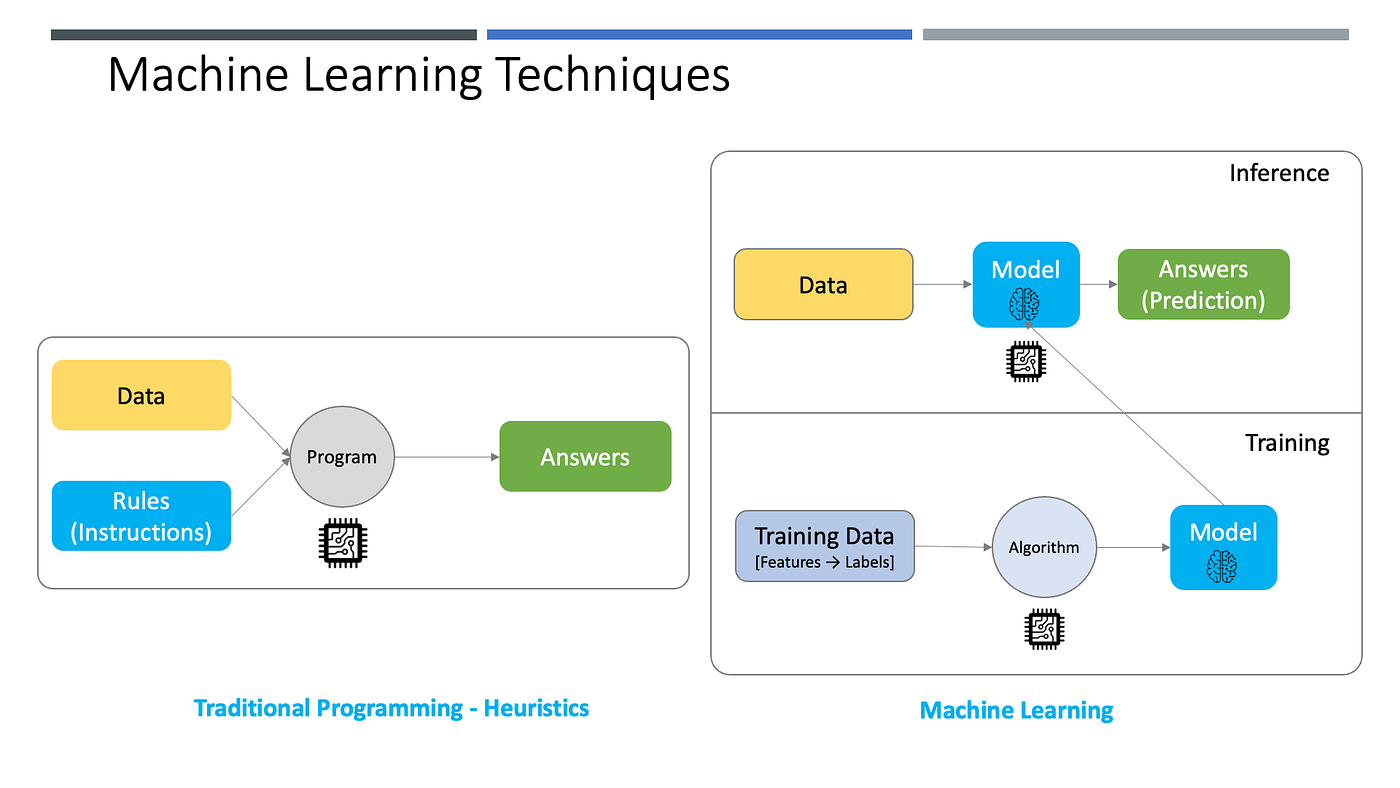
Machine Learning လုပ်တဲ့ Algorithms နည်းစနစ်တွေ များစွာရှိပါတယ်။ Linear Regression တို့၊ Vectorization ကိုအခြေခံတဲ့ နည်းစနစ်တွေ၊ Decision Tree တို့၊ Random Forest တို့၊ Deep Learning နည်းစနစ်တွေ များစွာရှိပါတယ်။ နောက်ပိုင်းခေတ်စားလာတာ ကတော့ Ensemble လို့ခေါ်တဲ Algorithms တစ်ခုမကကို ထပ်ဆင့်သုံးတဲ့ နည်းလမ်းတစ်မျိုး ဖြစ်ပါတယ်။
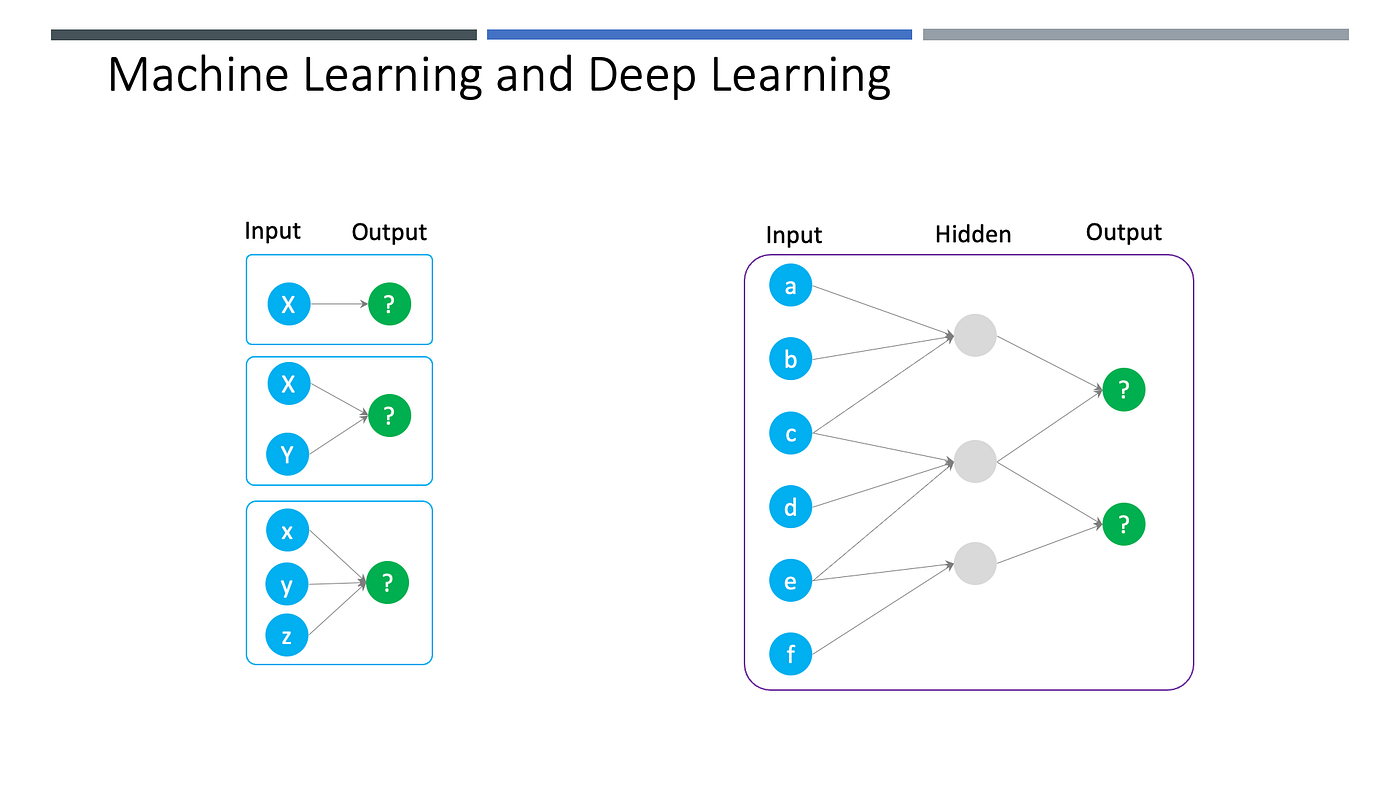
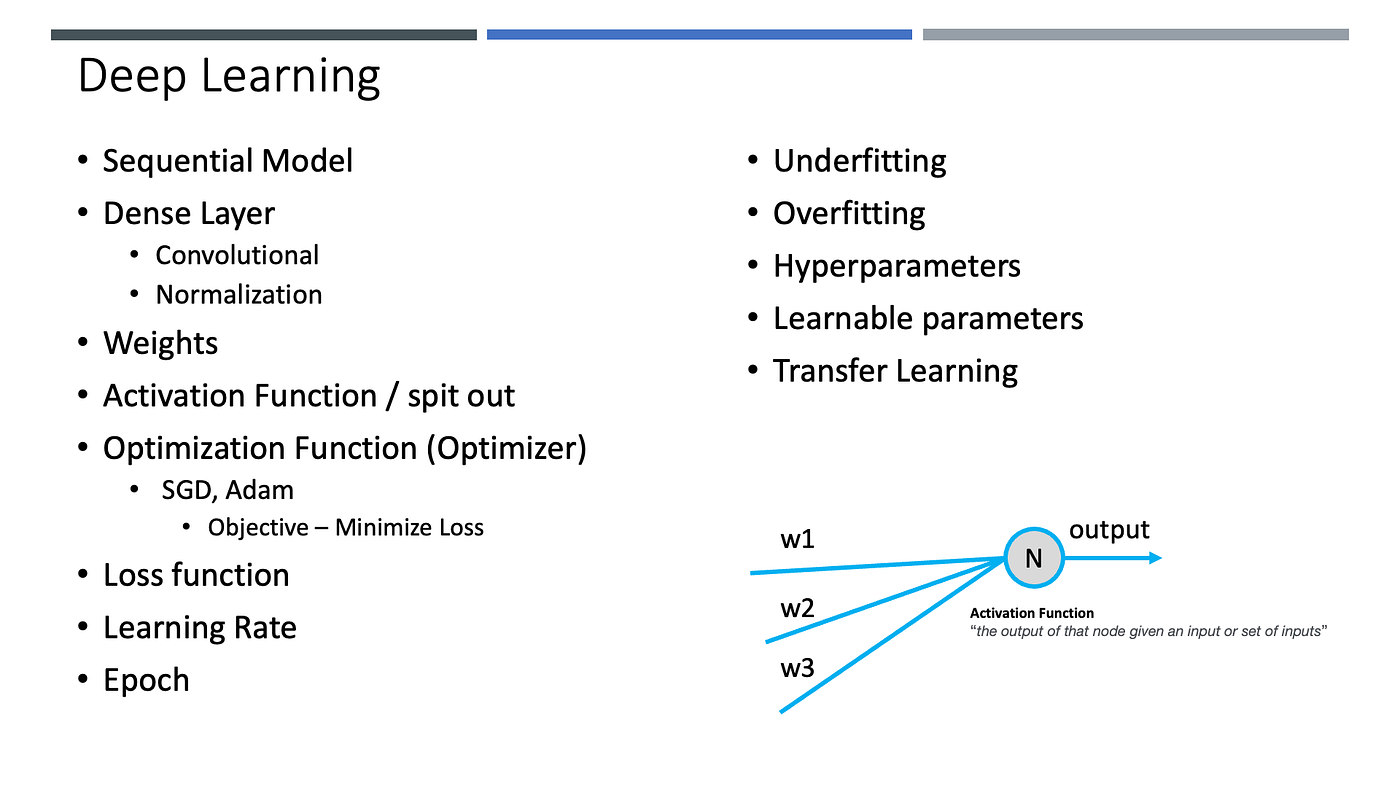
Neural Network နည်းစနစ်ကတော့ လူသားတွေရဲ့ ဦးနှောက်ကို အတုယူထားတဲ့ပုံစံမျိုးဖြစ်ပါတယ်။ Deep Learning (နက်နဲလေ့လာမှု) ဟုလည်းခေါ်ဝေါ်ကြပြီး၊ ဒီနည်းလမ်းမှာတော့ Layers အလိုက် Nodes တွေကိုအသုံးပြုပါတယ်။ Input အဝင်ကို Input Layer ၊ Output အထွက်ကို Output Layer နဲ့ ကြားရှိ Layers များကို Hidden Layers လို့ခေါ်ဆိုကြပါတယ်။ Model ကို Training ပြုလုပ်တဲ့အခါမှာ ဒီ Nodes တွေ ကြားမှာရှိတဲ့ wegiths တွေကို Backpropagation ပြုလုပ်ပြီး Optizmize ပြုလုပ်ပြီးတွက်ချက်ရယူပေးတာဖြစ်ပါတယ်။ အနည်းဆုံး Loss အမှားရှာတဲ့ ပုံစံအသုံးပြုကြပါတယ်။ အသေးစိတ်လေ့လာချင်တယ်ဆိုရင်တော့ ဒီ (Keras with TensorFlow Course — Python Deep Learning and Neural Networks) Tutorial ကိုကြည့်ပြီးလေ့လာနိုင်ပါတယ်။

Data Science လုပ်ငန်းစဉ်အစမှာ ပထမဦးဆုံးအနေဖြင့် အကောင်အထည်ဖေါ်ဖြေရှင်းရမဲ့ ရည်မှန်းချက်၊ ပြဿနာ (သို့) ပုစ္ဆာအမျိုးအစားတွေကို ခွဲခြားတတ်ဖို့လိုအပ်ပါတယ်။

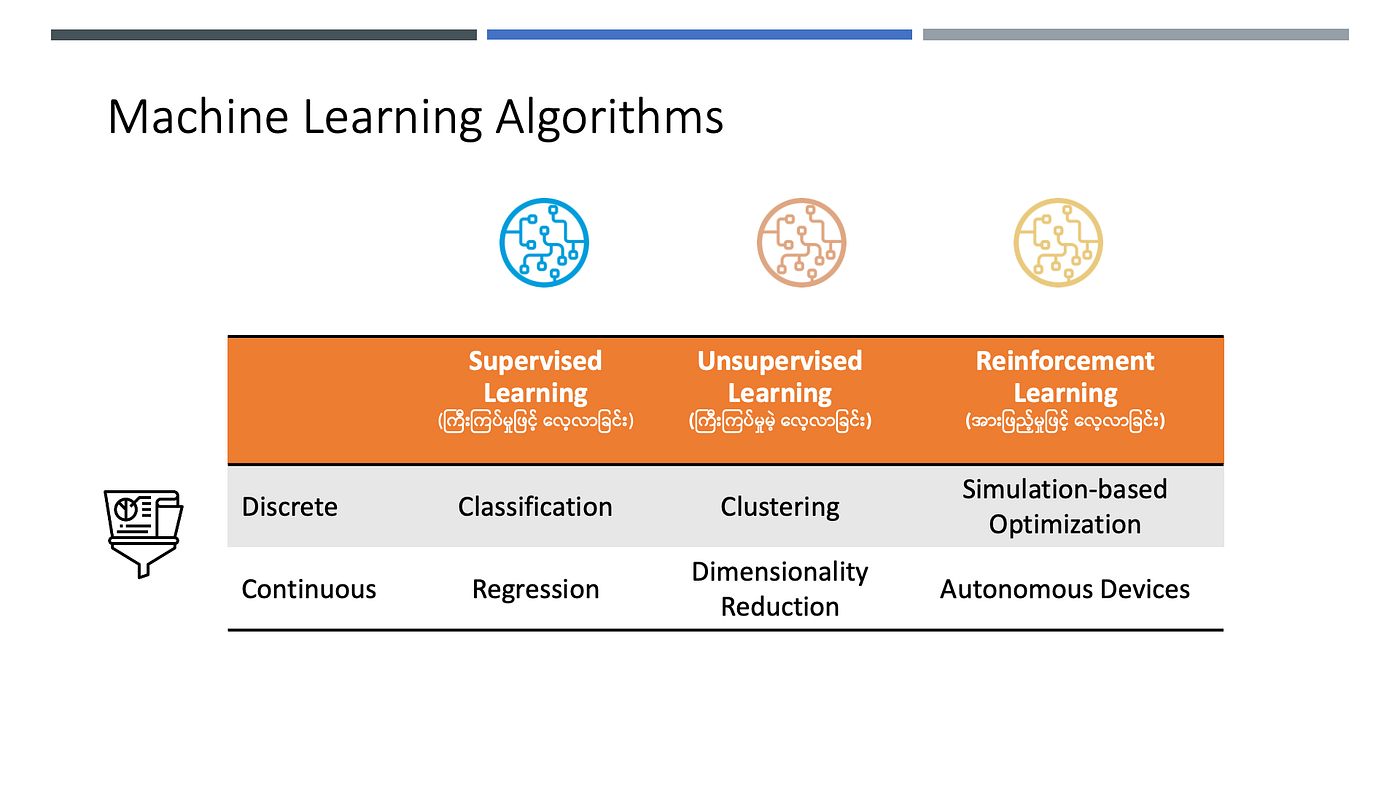
Machine Learning ဆောင်ရွက်ရာတွင် အချက်အလက်များအသုံးပြုပုံ ရှုထောင့်မှလည်း အောက်ပါအတိုင်း အမျိုးအစားခွဲခြားသတ်မှတ်နိုင်ပါတယ်။ Supervised Learning (ကြီးကြပ်မှုဖြင့် လေ့လာခြင်း)၊ Unsupervised Learning (ကြီးကြပ်မှုမဲ့ လေ့လာခြင်း) နှင့် Reinforcement Learning (အားဖြည့်မှုဖြင့် လေ့လာခြင်း) တို့ဖြစ်ပါတယ်။ လေ့ကျင့်မှုကာလတွင် အသုံးပြုသော Training Dataset (လေ့ကျင့်မှုအချက်အလက်အစု) တွင် ခန့်မှန်းမှု၏ အဖြေကို ထည့်သွင်းပေးသောနည်းစနစ်ကို Supervised Learning (ကြီးကြပ်မှုဖြင့် လေ့လာခြင်း) ဟုခေါ်ဆိုပြီး၊ ခန့်မှန်းမှု၏အဖြေကို Dataset တွင်ထည့်သွင်းပေးခြင်းမရှိသောနည်းစနစ်ကို Unsupervised Learning (ကြီးကြပ်မှုမဲ့ လေ့လာခြင်း) ဟုခေါ်ဆိုပါသည်။ လေ့ကျင့်မှုကာလတွင် လုပ်ဆောင်မှုအပေါ် Positive Rewords (အပေါင်းအားဖြည့်မှု) နှင့် Negative Rewards (အနှုတ်အားဖြည့်မှု) ပေး၍ လေ့လာစေသောနည်းစနစ်ကို Reinforcement Learning (အားဖြည့်မှုဖြင့်လေ့လာခြင်း) ဟုခေါ်ဆိုပါတယ်။ Machine Learning နည်းစနစ် အမျိုးအစားတွေကို ရွေးချယ်တဲ့အခါမှာ၊ အသုံးပြုတဲ့ အချက်အလက် အမျိုးအစားပေါ်လည်း အခြေခံရပါမယ်။
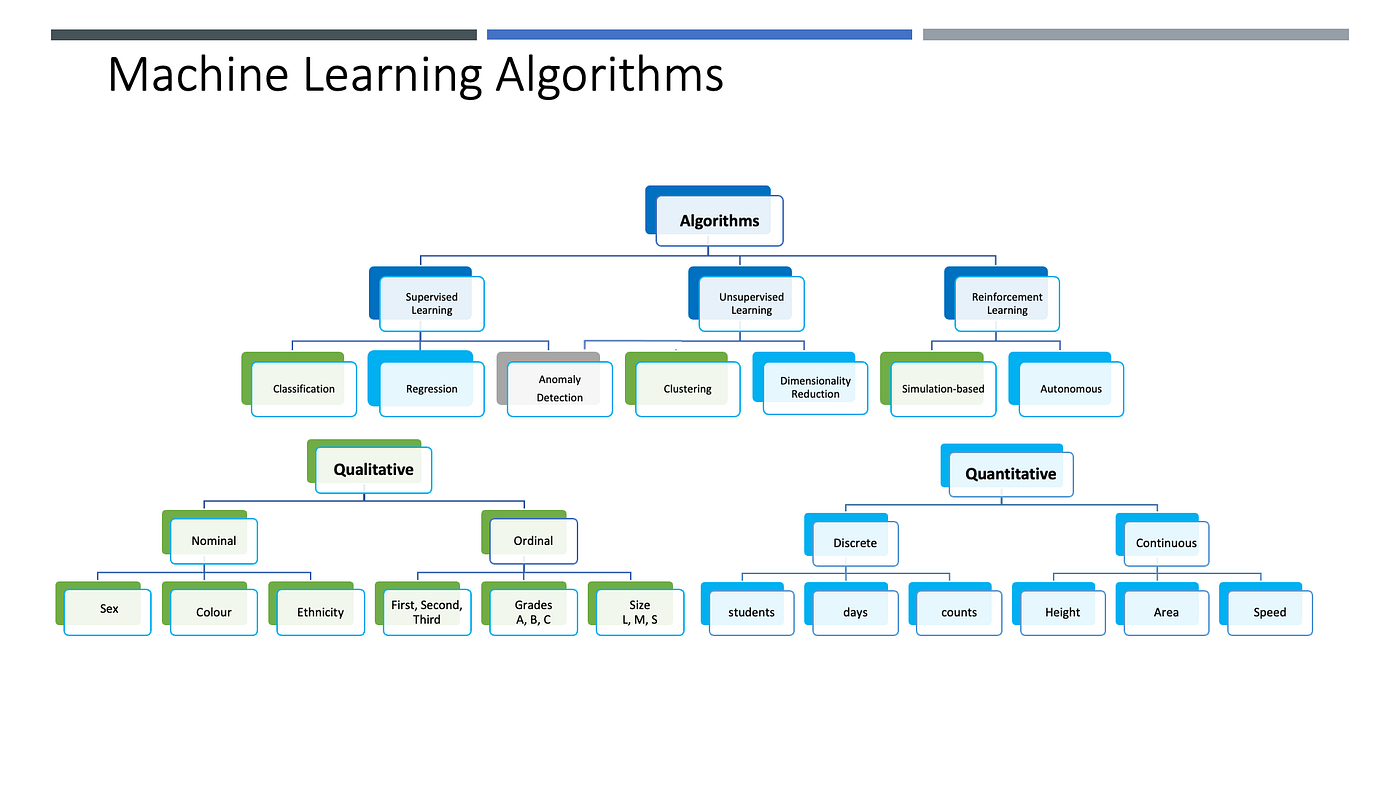
Machine Learning တွင်အသုံးပြုမည့် အချက်အလက်များကို Qualitative Data (အရည်အသွးအခြေခံသောအချက်အလက်) နှင့် Quantitative (အရေအတွက်အခြေခံသောအချက်အလက်) ဟူ၍ခွဲခြားထားပါတယ်။ Qualitative Data (အရည်အသွးအခြေခံသောအချက်အလက်) ကို ထပ်မံ၍ Ordinal Data (စဉ်၍ရသော အချက်အလက်) နှင့် Nominal (စဉ်၍မရသောအချက်အလက်) ဟူ၍ လည်းကောင်း၊ Quantiative Data(အရေအတွက်အခြေခံသောအချက်အလက်) ကိုလည်း ထပ်မံ၍ Discrete Data (ကိန်းပြည့်အချက်အလက်) နှင့် Continuous Data (ကိန်းစစ်အချက်အလက်) ဟူ၍ လည်းကောင်း အမျိုးအစားခွဲခြားသတ်မှတ်နိုင်ပါတယ်။
ဥပမာအနေနဲ့ Titanic သင်္ဘောခရီးသည်တွေရဲ့ အချက်အလက်တွေကို ကြည့်ပြီး ခရီးသည်တစ်ယောက်ချင်းစီရဲ့ အသက်ရှင်မရှင် ခန့်မှန်းတဲ့ ပုစ္ဆာတစ်ခုအဖြစ် လေ့လာလို့ရပါတယ်။


Feature Engienering ဆိုတာကတော့ Model ကို Training ပြုလုပ်ခြင်းမှာ အသုံးပြုမဲ့ အရေးကြီး အချက်အလက်တွေကို သုံးသပ်ပြီး အသုံးပြုမည့် Data Attributes များကို ရွေးချယ်သတ်မှတ်ခြင်း၊ ပြုပြင်သတ်မှတ်ခြင်းတို့ ပါဝင်ပါတယ်။ Feature Selection လို့ပြောရင်တော့ Independent Variables တွေ၊ Dependent Variables တွေကို ခွဲခြားပြီး သူတို့ရဲ့ Correlation အမျိုးအစားကို ခွဲခြားသုံးသပ်တာမျိုးတွေပါဝင်ပါတယ်။ Encoding ဆိုတာကတော့ Raw Data တွေကို Machine Learning ပြုလုပ်လို့ အဆင်ပြေအောင် ပြောင်းလဲသတ်မှတ်ပေးခြင်းမျိုး ဖြစ်ပါတယ်။
Model ကို Training ပြုလုပ်ပြီးတဲ့အခါမှာ ပြန်လည် Testing, Validation နှင့် Evaluation ပြုလုပ်ရန် လိုအပ်ပါတယ်။ Training ပြုလုပ်မဲ့ Dataset ကို ပိုင်းပြီး Cross Validation ပြုလုပ်လေ့ရှိပါတယ်။

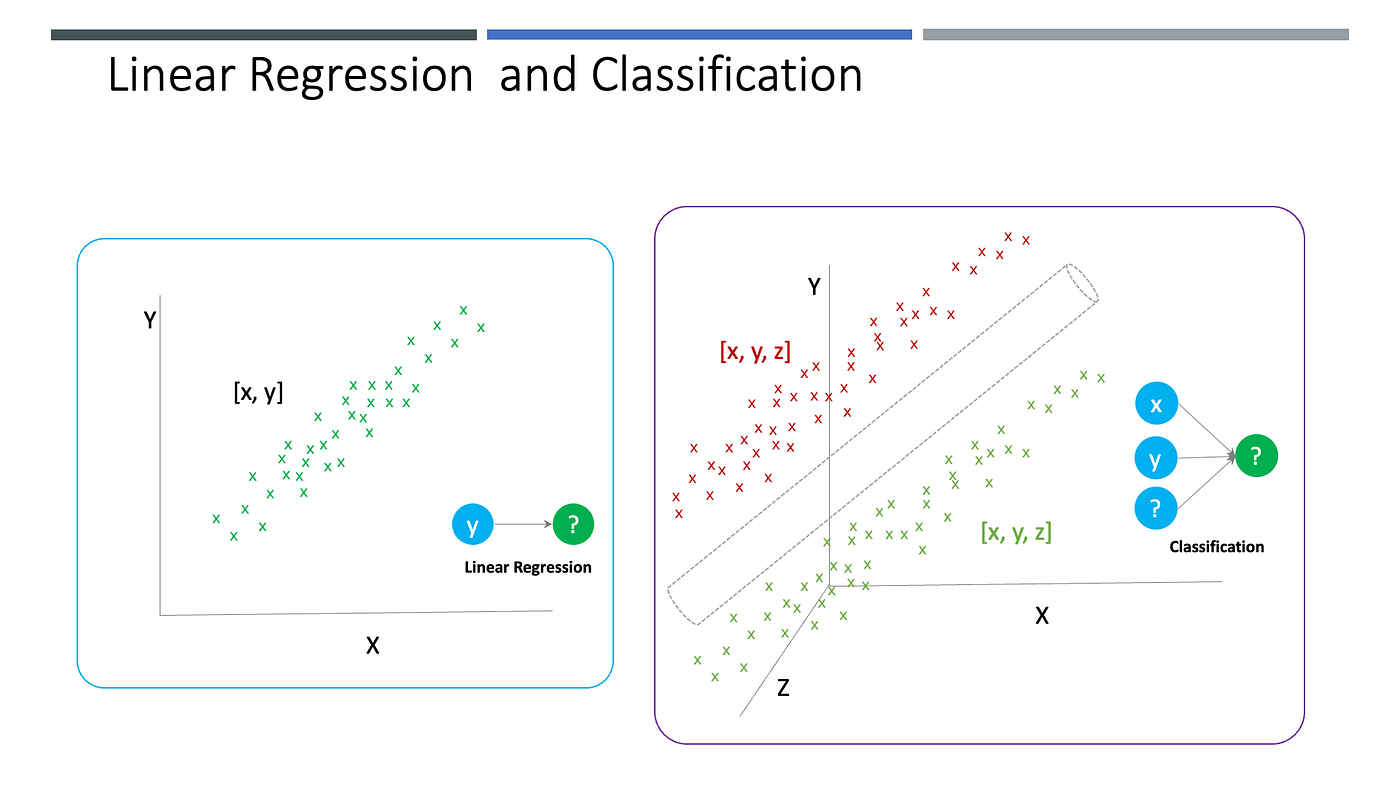
Model ၏ စွမ်းဆောင်နိုင်ရည် တိုင်းတာရာတွင် ပုစ္ဆာအမျိုးအစားပေါ်မူတည်၍ တိုင်းတာမှု Metric ကွဲပြားမှုရှိပါသည်။ Classification ကိုအသုံးပြုမဲ့ တိုင်းတာမှုနဲ့ Regression ကိုအသုံးပြုမဲ့ တိုင်းတာမှု မတူပါဘူး။ Accuracy, Precision, Recall, AUC တို့ကို Classification ပုစ္ဆာတွေမှာ သုံးပြီးတော့ MSE ကို Regression ပုစ္ဆာတွေမှာ အသုံးပြုကြပါတယ်။ Training Dataset တွင်နဲ့စမ်းရင် အောင်မြင်ပေမဲ့ တခြားပြင်ပ Dataset များနှင့် အသုံးပြုတဲ့အခါ မှားယွင်းတတ်တာကို Overfitting ပြဿနာလို့ ခေါ်ဆိုပါတယ်။ Model က Training Dataset ကို လှေနံဓါးထစ် မှတ်သားထားတဲ့ သဘောမျိုးဖြစ်ပါတယ်။ Underfitting ပြဿနာဆိုတာကတော့ Tranining Dataset ကိုတောင် အောင်မြင်အောင် မခန့်မှန်းနိုင်တာကို ဆိုလိုပါတယ်။

အချက်အလက်များသည် Model ဆောင်ရွက်နိုင်စွမ်း၏ အခြေခံဖြစ်သည့်အတွက် Data Drift (အချက်အလက်များ၏ အရွေ့အပြောင်း) ကို ပုံမှန် Monitoring စောင့်ကြည့်ပြီး Model ပြန်လည်တည်ဆောက်ဖို့ လိုမလို သုံးသပ်ရန်လိုအပ်ပါတယ်။

ယခုနောက်ပိုင်းတွင် Machine Learning platforms များကိုအသုံးပြုခြင်းအားဖြင့် Programming (သို့) Coding ရေးသားတတ်ရန်မလိုအပ်တော့ဘဲ Data Scicence လုပ်ငန်းစဉ်များကိုဆောင်ရွက်လာနိုင်သည်ကိုတွေ့ရပါတယ်။ Programing မရေးသားနိုင်သောသူ လူအများစုအနေဖြင့် အချက်အလက်များကို အသုံးချလာနိုင်ကြပြီး Data Science လုပ်ငန်းစဉ်များကို လုပ်ဆောင်နိုင်သည့်အတွက် Data Democratization ဟုလည်း တင်စားခေါ်ဝေါ်ကြပါသည်။
IDE နှင့် Code ရေးခြင်းပုံစံမျိုးမှ Notebook အသုံးပြုခြင်းသည် Data Scince လုပ်ငန်းစဉ်များအတွက် ပိုမိုလွယ်ကူထိရောက်စေပါသည်။
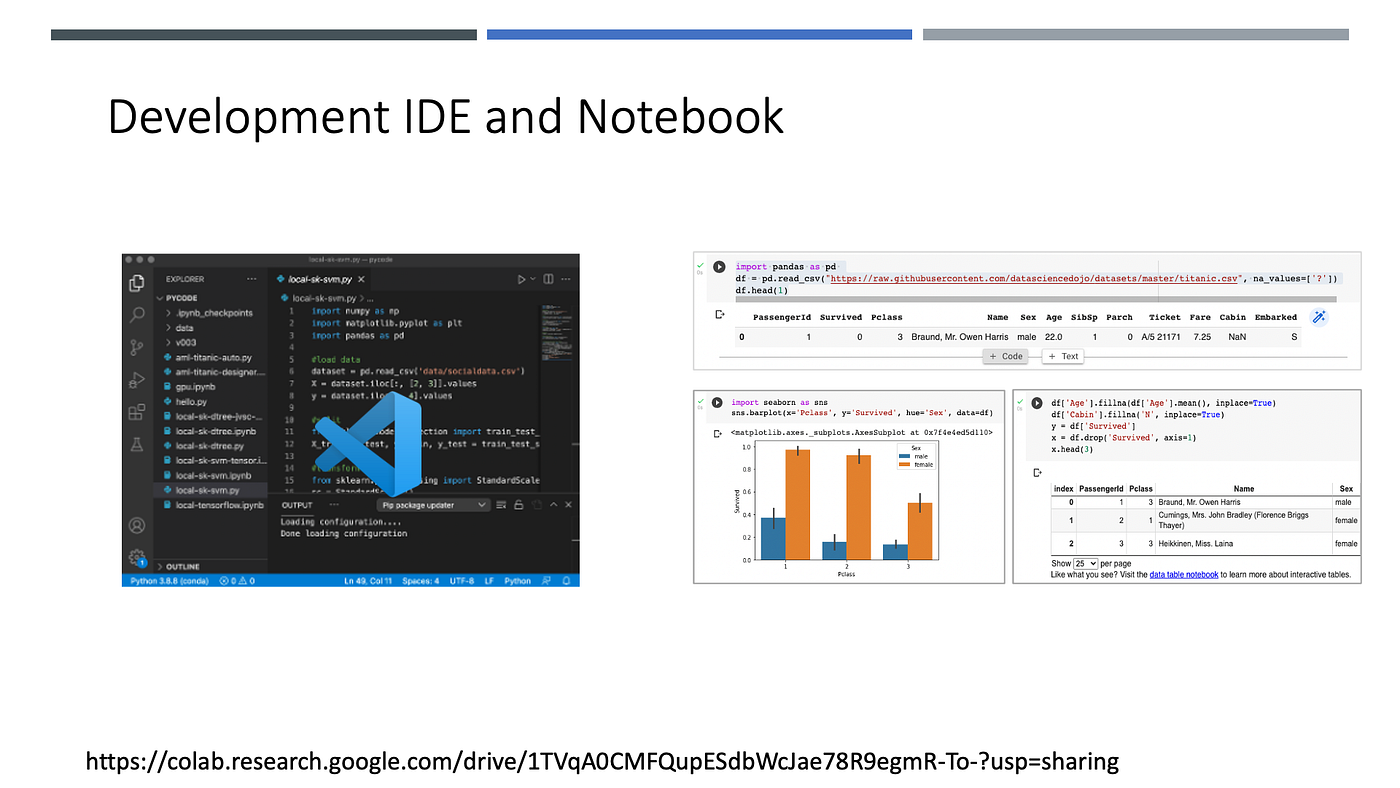
IDE အသုံးပြု၍ Data Science လုပ်ငန်းစဉ်များဆောင်ရွက်ခြင်း။
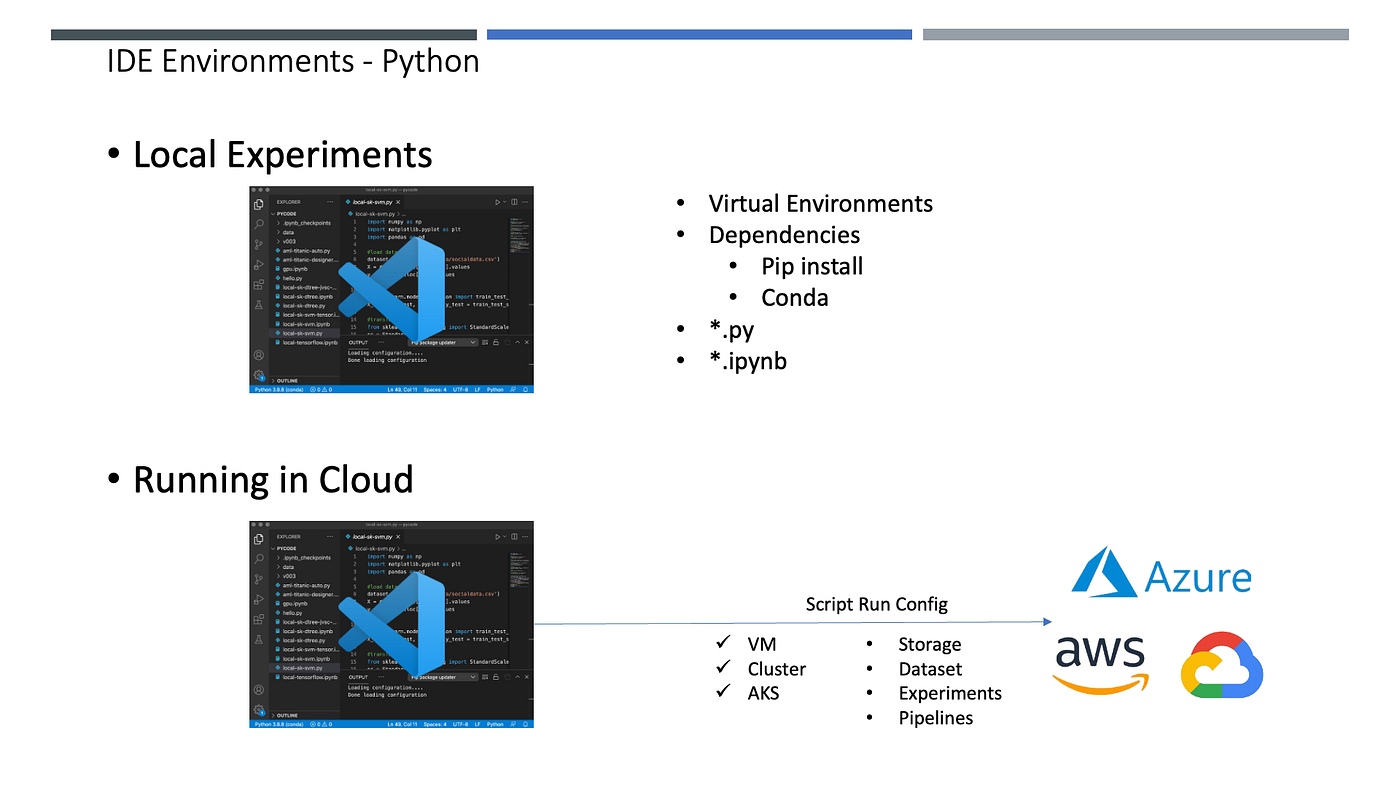
Notebook အသုံးပြု၍ Data Science လုပ်ငန်းစဉ်များဆောင်ရွက်ခြင်း။

အောက်မှာဖေါ်ပြထားတာကတော့ နားလည်လွယ်မဲ့ Notebooks ဥပမာလေးတွေ ဖြစ်ပါတယ်။ Google အကောင့်တစ်ခုရှိရုံနဲ့ စမ်းသပ် အသုံးပြုနိုင်မှာ ဖြစ်ပါတယ်။
- Tensorflow simple example
https://colab.research.google.com/drive/1kZAAiTTjVAnXzcAnFTt_5aItvqERtMCB?usp=sharing
- Decision Tree simple example
https://colab.research.google.com/drive/1TVqA0CMFQupESdbWcJae78R9egmR-To-?usp=sharing
•Visualisation simple examples
https://colab.research.google.com/drive/1FW26RGZPRxpAE6IDf4qjYQPc7zQ75dku?usp=sharing
•Comparison of different algorithms and how to use n-fold cross validation
https://colab.research.google.com/drive/1ywjDtaQprs8TJiuYAeCzLs3aXDR-zALj?usp=sharing
ScikitLearn PyTorch TensorFlow တို့ဟာ အသုံးများတဲ့ Machine Learning, Deep Learning Toolkits တွေဖြစ်ပါတယ်။ အခြားဥပမာများစွာပါဝင်သော Towards Data Science ကိုလည်း လေ့လာနိုင်ပါတယ်။
Data Science လုပ်ငန်းစဉ်များကို Cloud Machine Learning platform များဖြစ်သော Microsoft ၏ Azure Machine Learning Studio နှင့် AWS ၏ SageMaker တို့ကို အသုံးပြုပြီး ပိုမိုလွယ်ကူစွာ၊ ထိရောက်စွာ ဆောင်ရွက်နိုင်ပါတယ်။
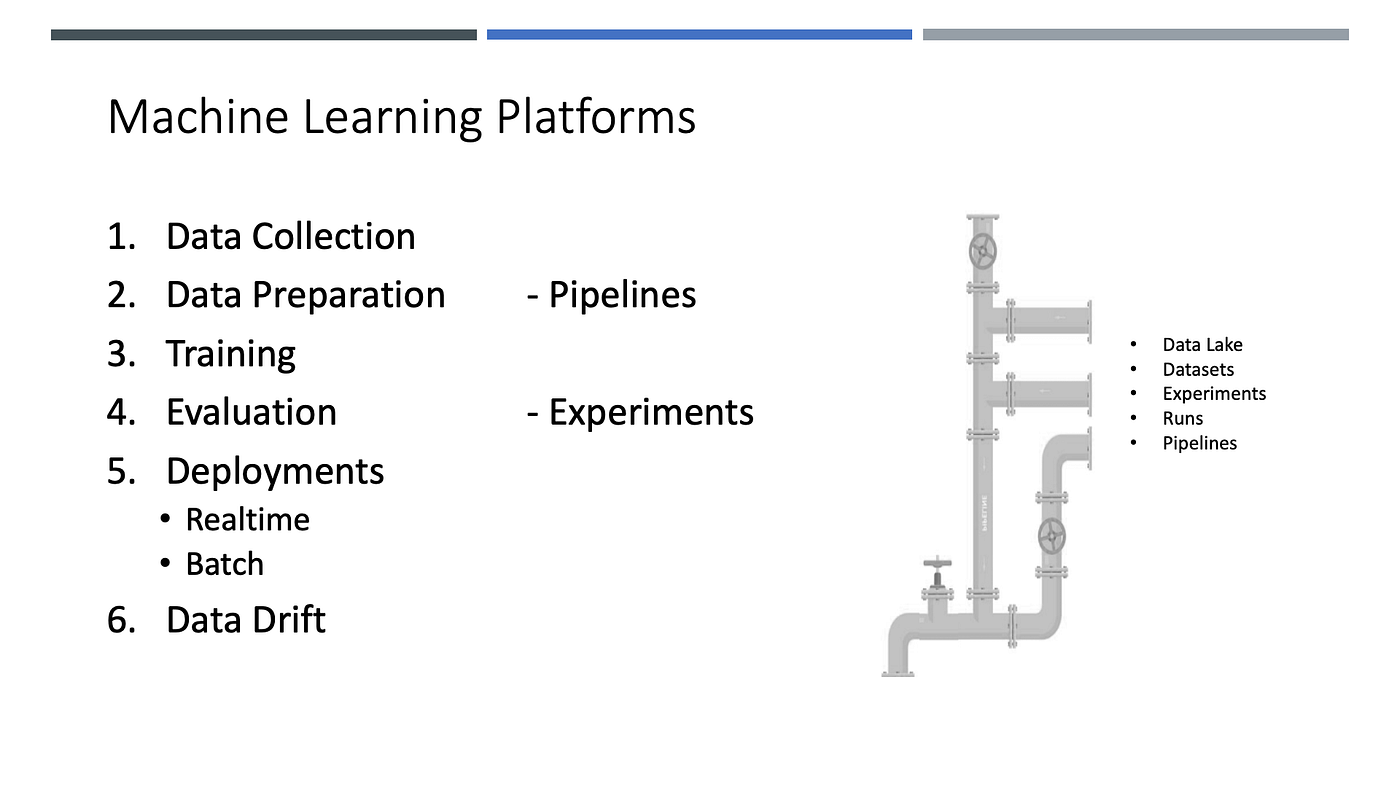
အခုရှင်းပြတဲ့အခါမှာ Microsoft ၏ Azure Machine Learning Studio ကိုအသုံးပြု ပြသသွားမှာဖြစ်ပါတယ်။

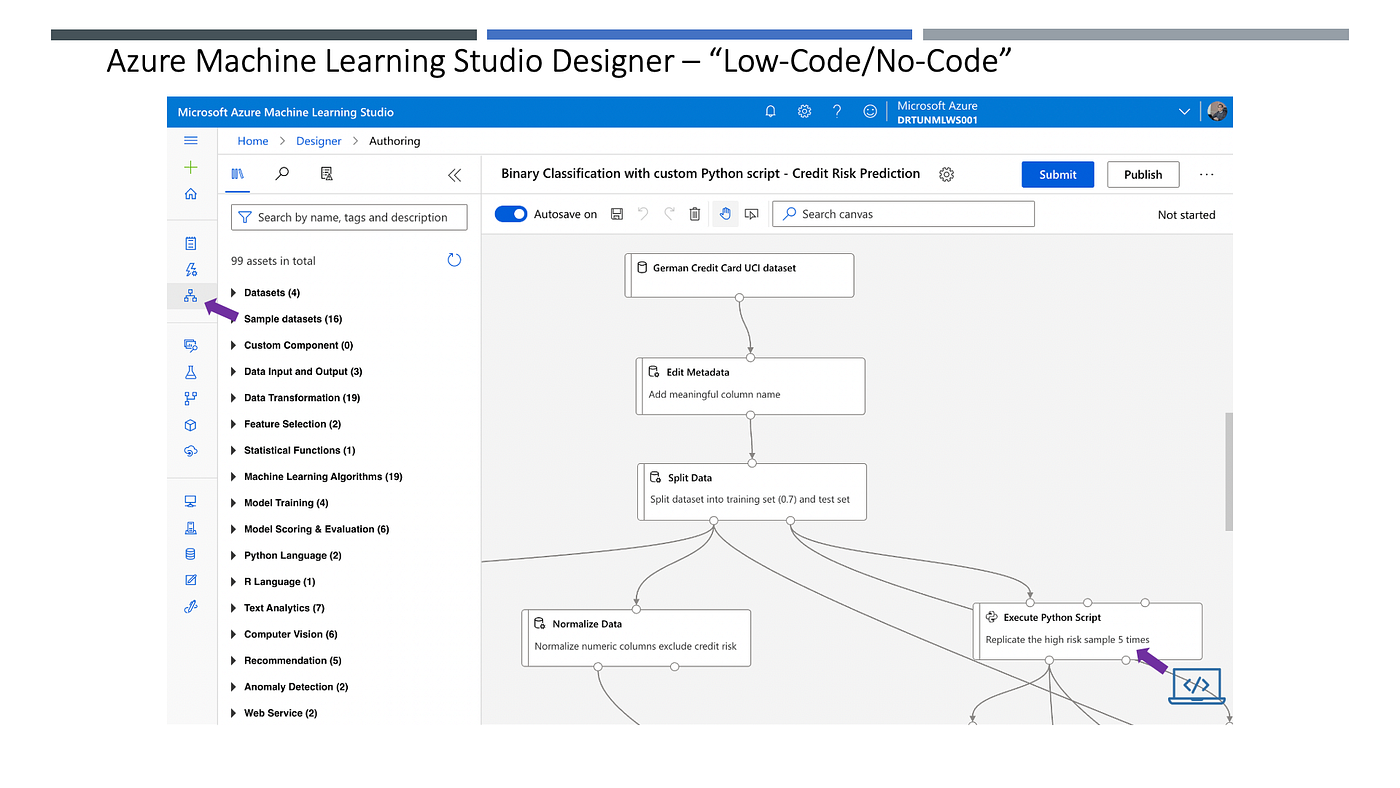
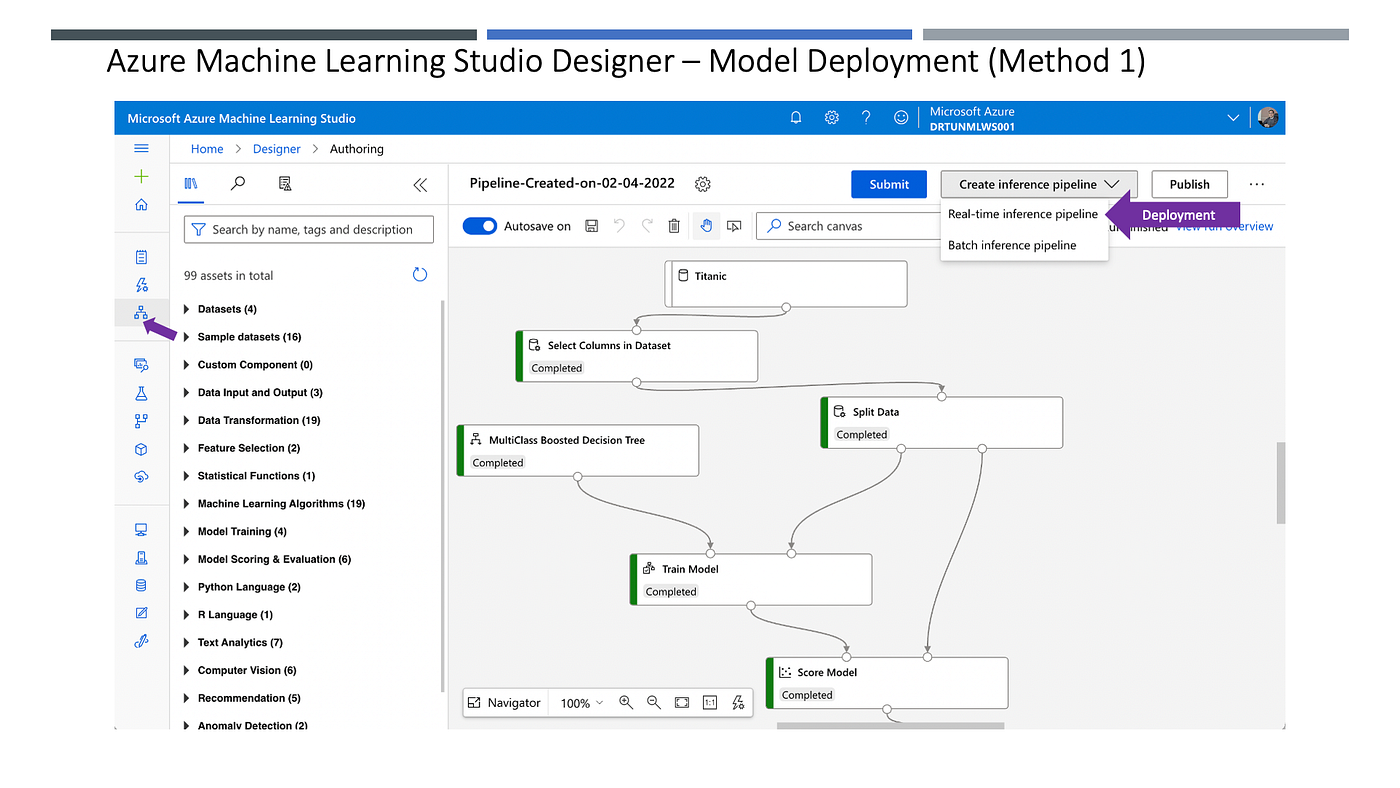
Azure ML Studio Designer အသုံးပြုလျှင် Code ရေးစရာမလိုဘဲ၊ Drag & Drop ပြုလုပ်ပြီး Data Science လုပ်ငန်းစဉ်များကို Pipelines တည်ဆောက်ပြီး Experiments များ ဆောင်ရွက်နိုင်ပါတယ်။လိုအပ်ချက်ရှိသည်အခါတွင် Code ထည့်ရေးခြင်းကိုလည်း ထည့်သွင်းဆောင်ရွက်နိုင်ပါတယ်။
အသုံးပြုရန် Deployment ပြုလုပ်ခြင်းသည်လည်း အလွန်လွယ်ကူပါတယ်။ Endpoint ကို Real-time အသုံးပြုမှုနှင့် Batch အသုံးပြုမှုပုံစံမျိုးအဖြစ် နှစ်မျိုးလုံးအသုံးပြုနိုင်ပါတယ်။
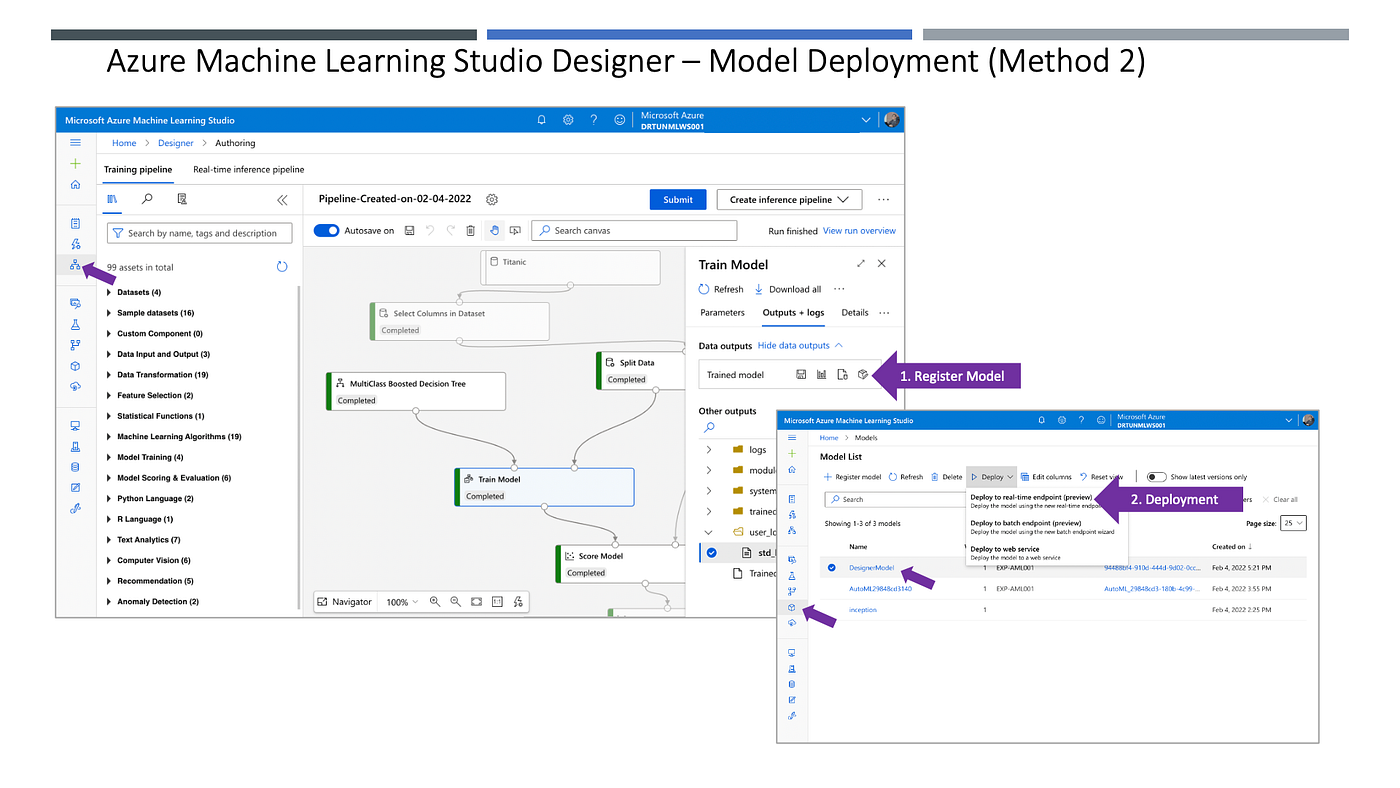
ဒုတိယနည်းအနေဖြင့် Model ကို Register ပြုလုပ်ပြီး၊ နောက်မှ Deployment ပြုလုပ်သည့်နည်းဖြစ်လည်း အသုံးပြုနိုင်ပါတယ်။
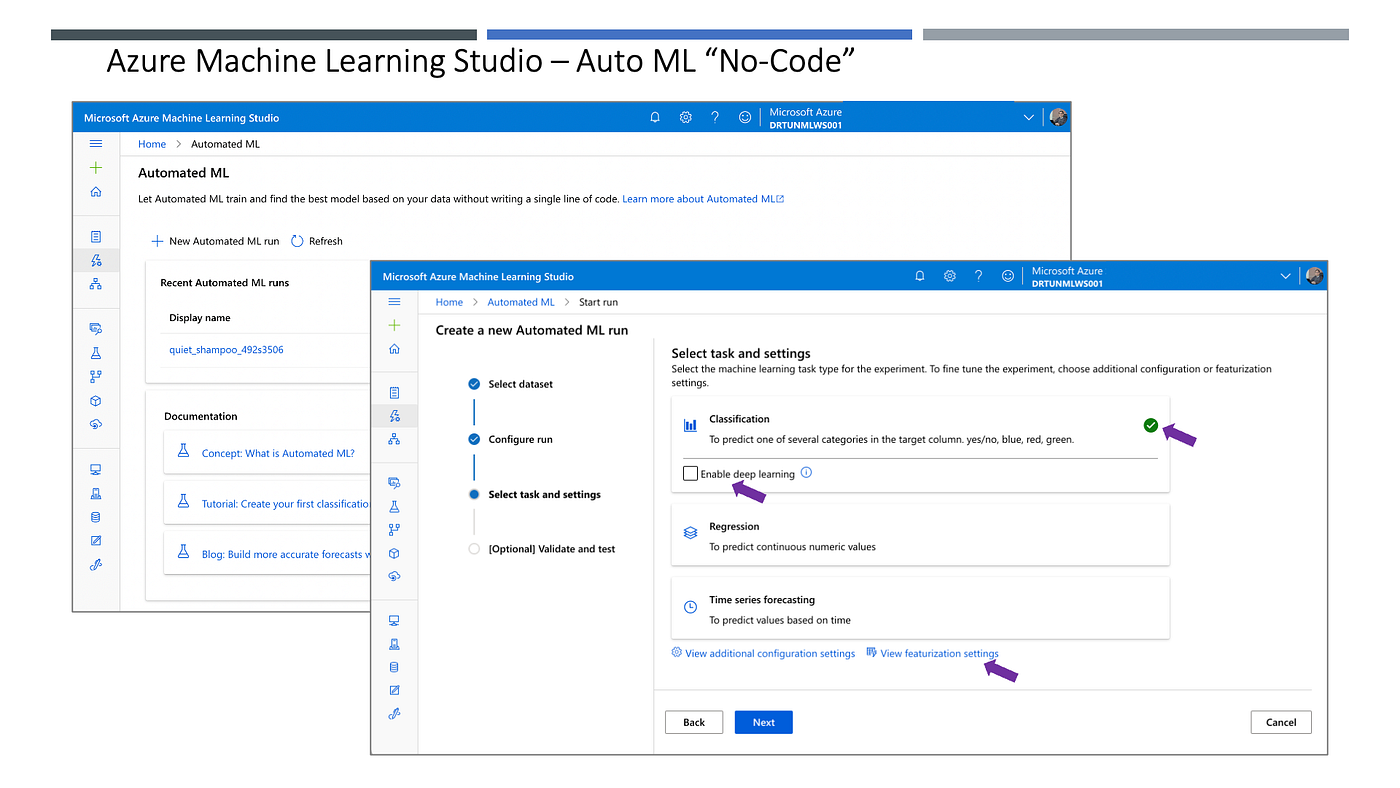
ဒါကတော့ Automated Machine Learning ဖြစ်ပါတယ်။ Auto ML လို့လည်း အတိုခေါ်ပါတယ်။
အသုံးပြုမဲ့ Dataset ကိုရွေးချယ်ပြီး၊ ဘယ် Attribute ကို Predict လုပ်မှာလည်း ဆိုတာကို သတ်မှတ်ရွေးပေးပြီ၊ ကန့်သတ်ချက်တစ်ချို့သတ်မှတ်ပေးလိုက်ရုံနဲ့ Machine Learning လုပ်ငန်းစဉ်အားလုံးကို အလိုအလျှောက် လုပ်ပေးသွားနိုင်ပါတယ်။
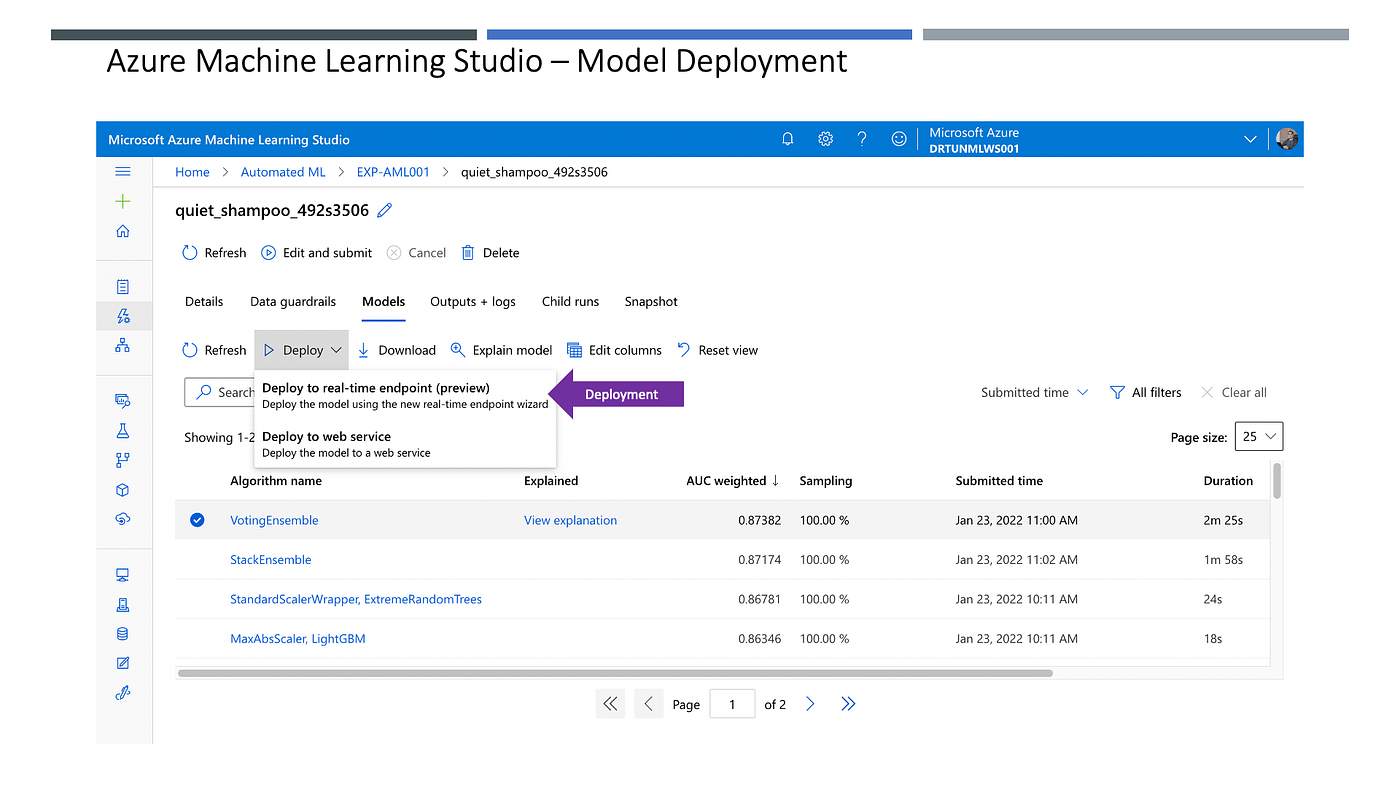
ဒါကတော့ Auto ML မှထွက်လာတဲ့ အကောင်းဆုံး Model ကိုရွေးချယ်ပြီး Deploy ပြုလုပ်ခြင်းပဲ ဖြစ်ပါတယ်။
အခုနောက်ပိုင်း အရေးကြီးသည့်အတွက် ပြောလာကြတာကတော့ Responsible AI ပဲဖြစ်ပါတယ်။ တရားမျှတမှုရှိခြင်း၊ အများပါဝင်နိုင်ခြင်း၊ ပွင့်လင်းမြင်သာမှုရှိခြင်း၊ ကိုယ်ပိုင်အချက်အလက်တွေကို ကာကွယ်ပေးနိုင်မှုနှင့်လုံခြုံမှုရှိခြင်း၊ စိတ်ချခိုင်မာမှုရှိခြင်း၊ တာဝန်ခံယူမှုရှိခြင်းတို့ကို အားလုံး သေသေချာချာ စီစဉ်ဖို့ လိုအပ်ပါတယ်။
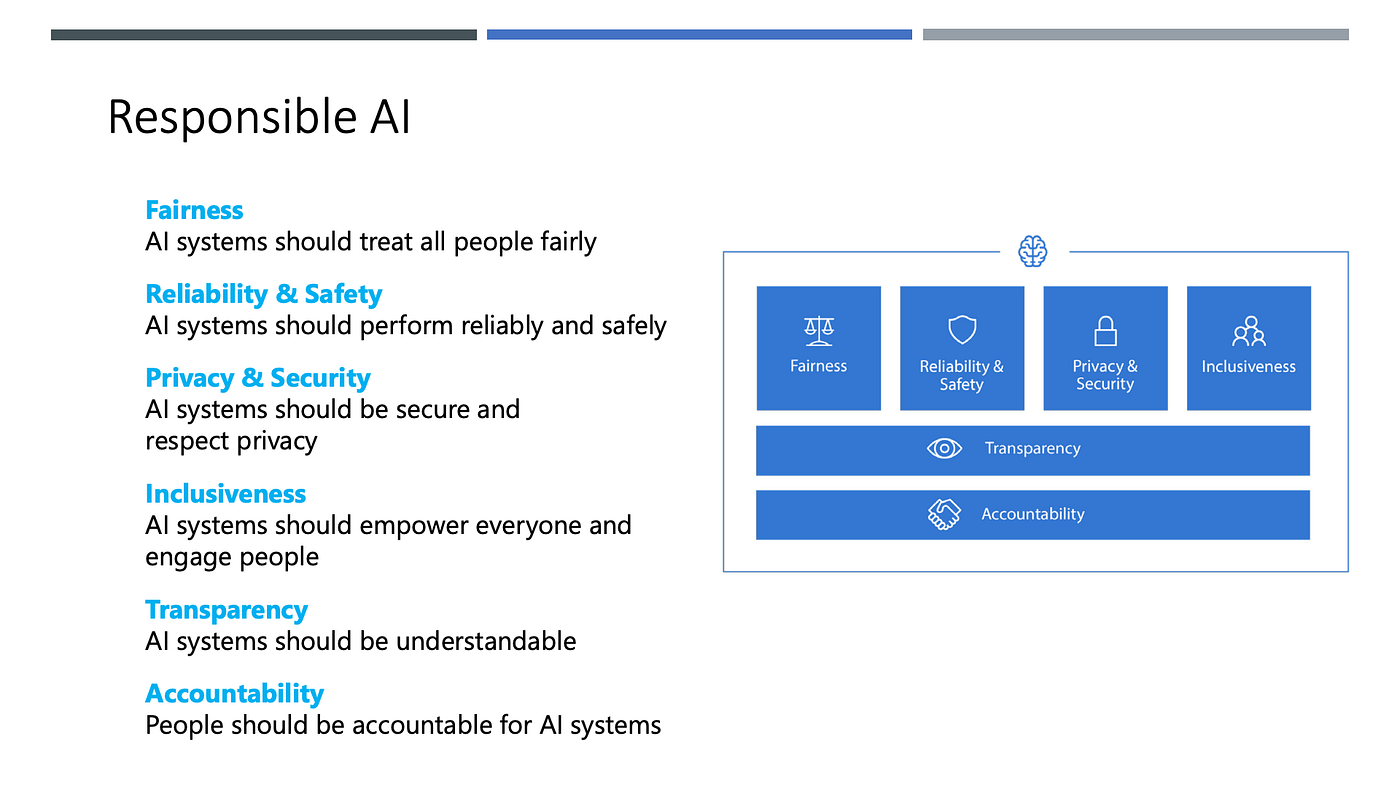
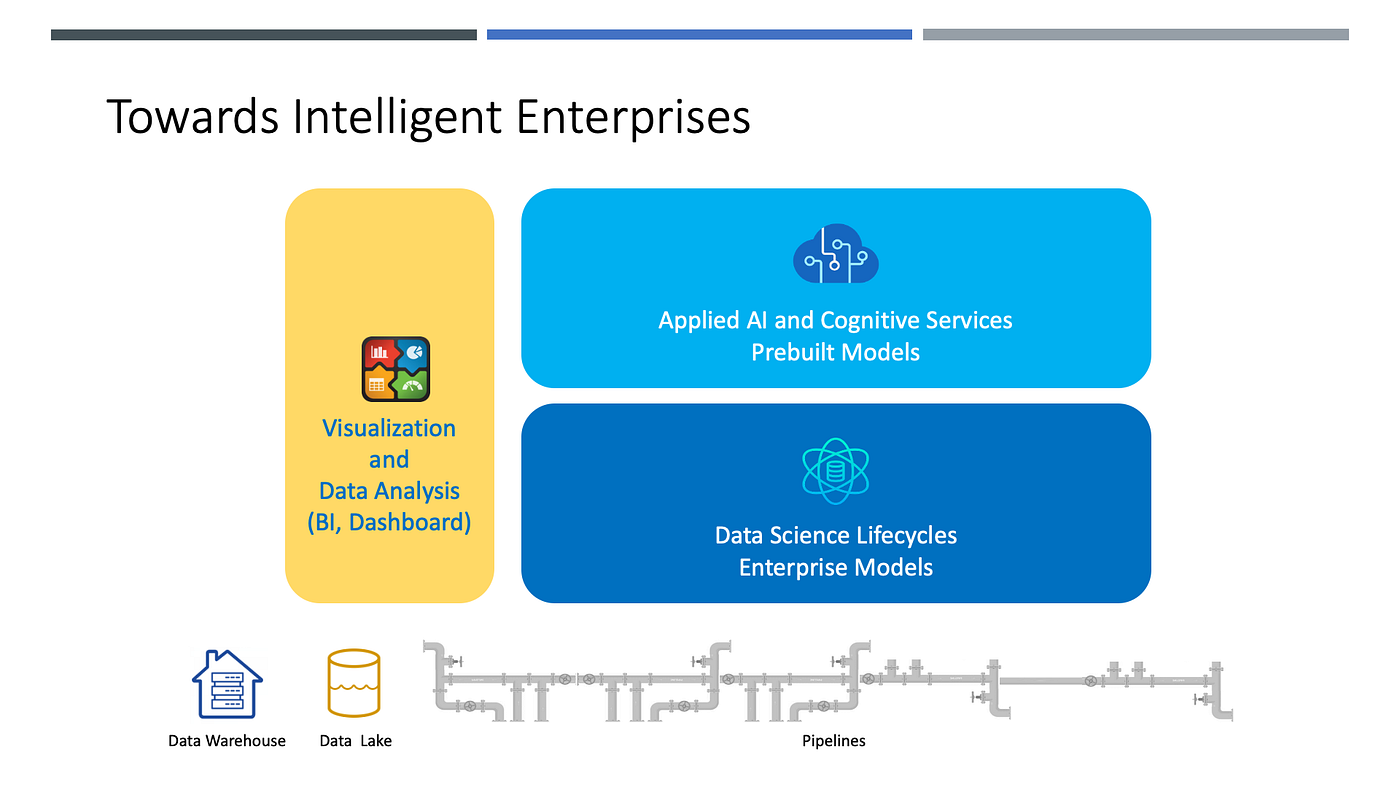
AI ကို အသုံးပြုကြတဲ့ အသုံးပြုမှုကဏ္ဍများနဲ့ စတင်အကောင်အထည်ဖေါ်လို့ရမည့် ပုံစံတွေဖြစ်ပါသည်။
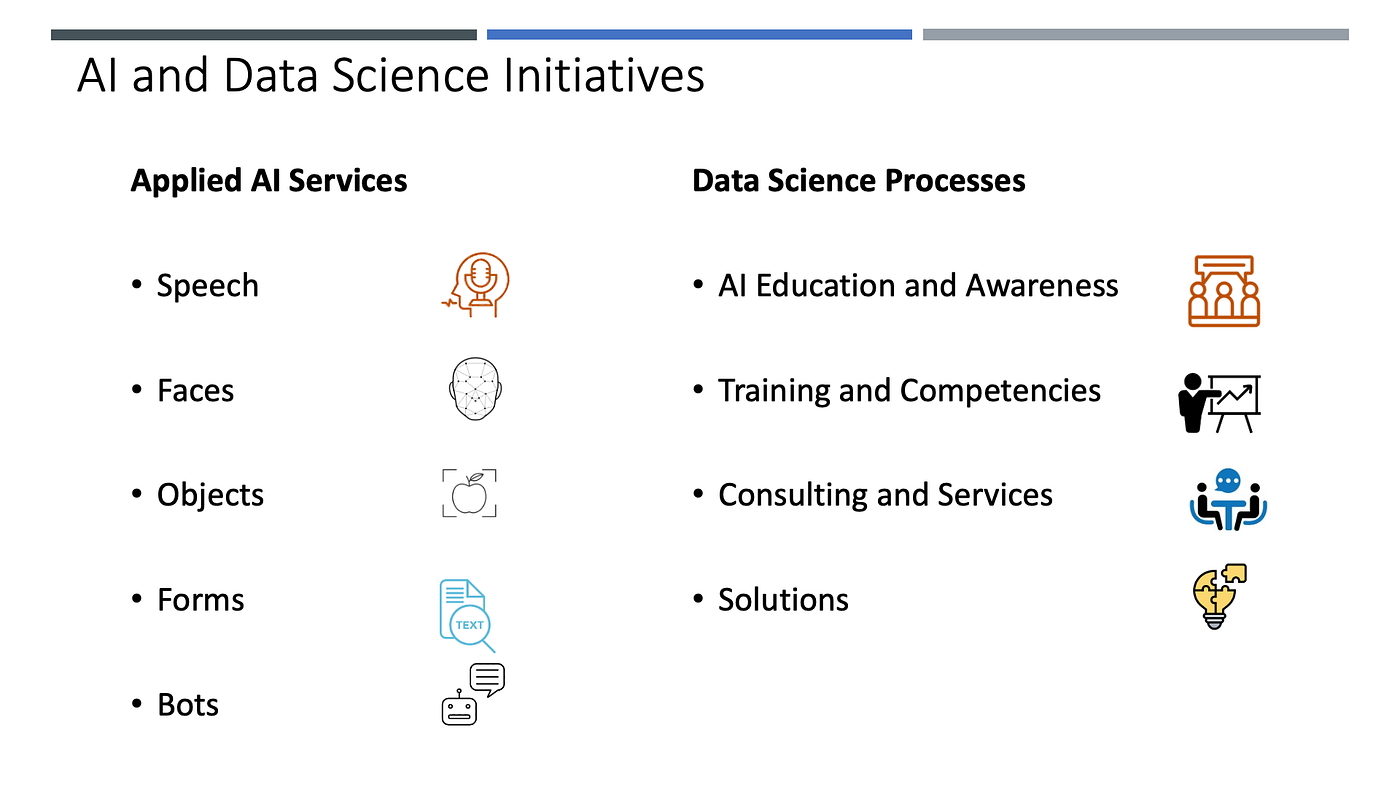
AI နဲ့ပတ်သက်တဲ့ အခြေခံ Awareness ရှိဖို့၊ နားလည်သိရှိထားဖို့ လိုအပ်ပါတယ်။ ကျွမ်းကျင်မှု Competencies တွေရှိဖို့လိုတယ်။ AI ကိုမိမိလုပ်ငန်းမှာ ဘယ်လိုအသုံးချလို့ ရနိုင်မယ်ဆိုတဲ့ Vision အမြင်တွေ ရှိဖို့လိုပါတယ်။ Data Science ဆိုတာ အချိန်အပိုင်းအခြားတစ်ခုသာ လုပ်ရမဲ့ Project မျိုး မဟုတ်ပါဘူး။ လုပ်ငန်းခရီးတောက်လျှောက် ဆက်တိုက်လုပ်ဖို့ လိုအပ်ပါတယ်။
Disruptive Innovation ဆိုတာ လက်ရှိလုပ်နေတဲ့နည်းလမ်းတွေကို စွန့်လွှတ်ပြီး တီထွင်စမ်းသစ်တဲ့ ပုံစံမျိုးဖြစ်ပါတယ်။ First Principles ဆိုတာကတော့ ကြားခံယူဆချက်တွေကိုဖယ်ရှားပြီး အခြေခံကျကျ အရာအားလုံးကို စဉ်းစားသုံးသပ်တာဖြစ်ပါတယ်။ Design Thinking ဆိုတာကတော့ စားသုံးသူတွေအတွက် လိုအပ်ချက်နဲ့အကျိုးကျေးဇူးကို အဓိကထားတဲ့ စမ်းသစ်မှုကို ဆိုလိုတာဖြစ်ပါတယ်။ ဒီလိုမျိုး စဉ်းစားတွေခေါ် စမ်းသစ်နိုင်မှပဲ Data Science လုပ်ငန်းစဉ်များအောင်မြင်နိုင်ပြီး၊ Intelligent Enterprise လို့ခေါ်တဲ့ အဖွဲ့အစည်းတွေ အဖြစ်ပြန်လည်မွေးဖွားလိုနိုင်မှာ ဖြစ်ပါတယ်။

Data Scientist တစ်ဦးအဖြစ် ဆက်လက်လေ့လာချင်တယ်ဆိုရင်တော့ Azure Data Scientist နှင့် AWS Machine Learning Specialty ကဲ့သို့သော Profession Certifications တို့ကိုဖြေဆိုထားသင့်ပါတယ်။
Microsoft Certified: Azure Data Scientist Associate

AWS Certified Machine Learning — Specialty Certification

AI Engineer တစ်ဦးအဖြစ် ဆက်လက်လေ့လာချင်တယ်ဆိုရင်တော့ Azure AI Engineer ကဲ့သို့သော Profession Certifications တို့ကိုဖြေဆိုထားသင့်ပါတယ်။
Microsoft Certified: Azure AI Engineer Associate

အခြားစပ်လျှဉ်းတဲ့ ကျွမ်းကျင်မှုလမ်းကြောင်းတွေကတော့ Data Engineering နှင့် BI Analytics တို့ဖြစ်ကြပါတယ်။
Microsoft Certified: Azure Data Engineer Associate
Exam DA-100: Analyzing Data with Microsoft Power BI
Comments
Post a Comment